Курс по криптовалюте Doctors Coin: Новости Doctors Coin, Outlook, курс, обзоры, обзор.
Криптовалюта Doctors Coin (DRS)
DRS — это проприетарный цифровой актив платформы BeauBang. Платформа в первую очередь полагается на DRS для управления своей экономикой, обеспечения стабильности операций и компенсации всем участникам экосистемы за их вклад в экономику DRS. В дополнение к другим вариантам использования токенов, DRS также можно продавать и обменивать на другие криптовалюты.
Что такое BeauBang?
BeauBang — это социальная платформа электронной коммерции косметических товаров и услуг. Это место, где собираются люди из всех слоев общества, чтобы петь и культивировать красоту. Покупатели и продавцы взаимодействуют друг с другом и заключают сделки, в то время как рекламодатели и влиятельные лица продвигают свои бренды и бутики.
Миссия
Doctors Coin стремится улучшить индустрию красоты для всех энтузиастов красоты, магазинов и влиятельных лиц.
Благодаря технологии блокчейн платформа DRS устраняет необходимость в посредниках и упрощает одноранговые, немедленные и безграничные платежи в секторе здравоохранения. Пользователи могут пользоваться преимуществами системы без комиссии и целостности данных транзакции.
Достоинства платформы
Доступная красота. Теперь у покупателей будут средства для доступа к косметическим товарам из-за границы.
Качественная продукция. На BeauBang будут представлены косметические товары от известных брендов и бутиков.
Хозяйственные операции. Doctors Coin устраняет необходимость в посредниках, позволяя проводить более дешевые транзакции.
Социальные взаимодействия. Пользователи могут использовать Doctors Coin как средство сбережения и отправлять их своим коллегам.
Технология
Doctors Coin использует различные технологические тенденции, чтобы обеспечить беспрепятственный перенос активов и беспроблемный опыт для всех пользователей платформы. Для этого применяют:
Интеграция с блокчейном. Doctors Coin реализует технологию блокчейн для повышения безопасности и скорости платежных транзакций в своей экосистеме.
Смарт-контракты. Команда использует смарт-контракты для проверки точности и законности каждой транзакции в рамках экономики этой платформы DRS.
Протокол XPC. Новый протокол XPC был реализован на социальной платформе BeauBang, чтобы упростить использование бумажных денег и криптовалюты для покупки продуктов.
Алгоритм ECDSA. Алгоритм цифровой подписи с эллиптической кривой (ECDSA) также используется для криптографии с открытым ключом в DRS, чтобы обеспечить меньшую длину ключа.
Пункт взимания платы за проезд. Кошелек DRS был разработан как платформа для хранения криптовалюты DRS, позволяющая брендам здравоохранения продавать свои продукты.
Интернет-торговля социальными видео. BeauBang — это социальная платформа для электронной коммерции видео, где продавцы, рекламодатели и покупатели объединяются для совершения транзакций в блокчейне DRS.
Видение
«Doctors Coin станет одним из лидеров в области криптовалюты, поддерживая доступные высококачественные косметические продукты», — заявили разработчики.
Рекламодателям
DRS стремится помочь рекламодателям, торгующим медицинскими товарами, улучшить отслеживание рекламы и снизить расходы на рекламу благодаря технологии блокчейн.
Продавцам
DRS стремится помочь поставщикам медицинских услуг узнать больше об их продуктах через социальную видеоплатформу BeauBang.
Покупателям
DRS стремится помочь покупателям приобретать товары для здоровья и красоты по более низкой цене с помощью структуры оплаты без комиссии.
Токеномика
Doctors Coin (DRS) — это основной актив, используемый для финансирования экономики платформы и компенсации всем участникам экосистемы за их вклад. Рекламодатели также могут использовать его в качестве вознаграждения для пользователей, которые увидят их видеообъявления.
Хотя платформа позволяет использовать фиатные деньги и другие криптовалюты, DRS пользуется большой поддержкой в качестве приоритетного актива. Пользователи, которые платят фиатными деньгами на традиционных платежных шлюзах, должны будут иметь дело с другими обременительными факторами, которые можно устранить, если они будут платить с помощью DRS через платформу BeauBang.
DRS устраняет необходимость в посредниках, поскольку платежи будут полностью одноранговыми (P2P). Покупатели могут напрямую связываться с продавцами и переводить платежи с одного кошелька на другой, что позволяет снизить цены и платежи за счет меньшего количества людей, участвующих в транзакции.
«Помимо комиссии за транзакцию, могут возникнуть накладные расходы, которых можно избежать, особенно при совершении покупок за рубежом. Это можно смягчить с помощью технологии блокчейн. «Управление цепочкой поставок может стать проще, поскольку блокчейн может обеспечивать непрерывный и децентрализованный мониторинг товаров», — поясняют разработчики.
Наконец, DRS может разрешить немедленные платежи без границ. В отличие от традиционных платежных порталов, блокчейн использует децентрализованную базу данных для обеспечения целостности данных транзакций.
В текущем рейтинге CoinMarketCap DRS занимает 2772 место, при этом рыночная капитализация в реальном времени недоступна. Циркуляционной подачи нет, максимальное количество — 10 000 000 000 токенов DRS.
Основными биржами для торговли Doctors Coin в настоящее время являются Dcoin, VCC Exchange, ExMarkets, ProBit Global и VinDAX.
F1 2020: колеса как у Гамильтона, ускоритель как у Переса. Обзор Такова специфика ежегодно лицензируемых тренажеров — команда разработчиков создает переломный момент в серии, существенно изменяя
⇡#Как хочу, так болид и кручу
Что, безусловно, радует подход Codemasters, так это то, что F1 (а не только 2020), несмотря на то, что это игра об исключительно элитном виде спорта, доступна игроку любого уровня подготовки и знания предмета. Для заядлых поклонников сверхбыстрых гонок с периферийным рулевым управлением есть гоночный режим с условиями, максимально приближенными к настоящим гонкам! Здесь и реалистичная поломка машины, и механическая коробка передач со сцеплением и минимум помощи при вождении. Исход гонки с этими настройками также решается вне трассы, где на результат будут влиять десятки вариантов регулировки аэродинамической нагрузки, аэродинамическое управление передними и задними крыльями, стабилизация подвески, регулировка давления в шинах, регулировка дифференциала и многое другое более.
Те, кто не хочет часами настраивать малоизвестные параметры в ракетной мастерской, оценят упрощенный режим («нормальный», как его называет F1 2020), в котором внетрассовые покрытия не такие твердые, и есть разная степень поддержки со стороны игры. Помощь при торможении и входе в повороты, автоматический возврат на трассу при взлете и отображение динамической траектории значительно упрощают жизнь на трассе. Хотя, например, отдавать управление крылом компьютеру бесполезно, ИИ пользуется часто неуместным DRS. Конечно, услышав характеристики будущей звезды F1, любой параметр можно отключить по желанию.
Парк состоит из трех категорий на выбор: современные модели F1, прошлогодняя F2 и вечная классика, такая как Ferrari F1-90 или McLaren MP4-23
Вы, наверное, уже знаете, что автомобили Формулы 1 значительно изменят внешний вид в 2022 году из-за серьезного обновления правил. Основная цель

Глядя на две версии машины в профиль, становится ясно, что машина 2022 года намного проще с точки зрения аэродинамики. Отметим, что в 2022 году дополнительные аэродинамические элементы (различные крылья), интегрированные в кузов, вернутся на охлаждение.
На изображении это не показано, но вес автомобилей увеличится на 5%, с 752 кг до 790 кг. Почему? Во-первых, новые колеса тяжелее: четыре колеса и шины примерно на 14 кг тяжелее, чем в 2021 году. Еще одним фактором, влияющим на вес автомобиля, является повышение уровня безопасности: водители будут защищены лучше, чем когда-либо.
Все среды VMware vSphere сбалансированы по нагрузке с помощью vSphere Distributed Resource Scheduler (DRS). DRS объединяет узлы ESX и ESXi для обеспечения оптимальной балансировки нагрузки от работающих виртуальных машин (ВМ). DRS Scheduler — чрезвычайно эффективное решение, особенно для инфраструктур с большим количеством виртуальных хостов
Пять советов по управлению планировщиком DRS на платформе vSphere
Все среды VMware vSphere сбалансированы по нагрузке с помощью vSphere Distributed Resource Scheduler (DRS). DRS объединяет узлы ESX и ESXi для обеспечения оптимальной балансировки нагрузки от работающих виртуальных машин (ВМ). DRS Scheduler — чрезвычайно эффективное решение, особенно для инфраструктур с большим количеством виртуальных хостов
… Если бы не встроенные средства автоматизации, оператору пришлось бы решать постоянно актуальную проблему правильного размещения виртуальных машин на хостах, а известно, что никто не может сделать это так эффективно, как математические вычисления формула вместе с «командой» высококачественных мониторов.
На первый взгляд планировщик DRS кажется в высшей степени примитивным продуктом, но вы будете удивлены, узнав, сколько вычислений выполняется под его дискретной оболочкой. Интерфейс продукта может показаться излишне упрощенным, но его освоение потребует определенных усилий, точности и большого терпения. Требуются усилия, чтобы правильно настроить продукт; если вы введете неверные параметры, продукт не сможет выполнять свою работу. Следует проявлять осторожность, чтобы избежать чрезмерного упрощения функций планировщика; слишком сильные ограничения могут сделать невозможным выполнение балансировки нагрузки.
важно внимательно просмотреть настройки DRS, а также ряд других настроек, которые могут вызвать проблемы. В некоторых случаях попытка управления кластером может принести больше вреда, чем пользы. Если вы хотите избежать подобных ошибок, ознакомьтесь с приведенными ниже рекомендациями, которые помогут вам успешно работать с DRS.
Совет № 1. Не считайте себя умнее DRS
Однажды, когда один из моих коллег-консультантов сказал, что ручное выравнивание нагрузки легко превзойдет автоматизированные инструменты DRS, я заключил с ним пари, что автоматизированный планировщик выиграет. По словам моего коллеги, он установил уровень автоматизации DRS вручную, потому что заранее проверил все счетчики и разместил виртуальные машины там, где они должны быть. Он считал, что DRS не сможет найти более эффективных настроек. Он также не верил в автоматизацию планировщика DRS.
Я убедил коллегу переместить уровень автоматизации с ручного на полностью автоматизированный и настроить порог миграции для применения рекомендаций Priority 1, Priority 2 и Priority 3, как показано на рисунке 1. Этот параметр, доступ к которому можно получить через VMware DRS узел в кластере экрана свойств переводит продукт в промежуточный режим между консервативным и агрессивным режимами.
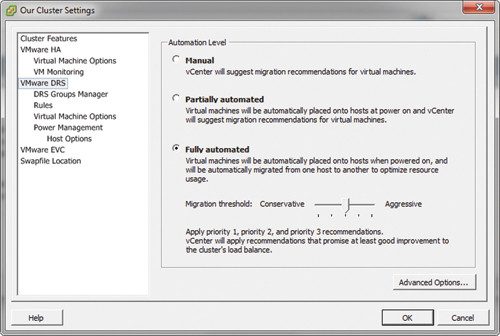 |
| Рисунок 1: Полностью автоматизированный порог миграции DRS |
Мы сделали другие вещи, и когда через несколько часов вернулись, было обнаружено, что во время оптимизации почти все виртуальные машины сменили своих «хозяев». Я выиграл спор.
Три уровня автоматизации DRS определяют степень контроля над перемещением виртуальных машин, назначенную DRS. Ручной режим не требует никаких действий; планировщик просто дает совет. Частично автоматический режим вступает в силу только в том случае, если виртуальные машины были запущены ранее. В этих двух случаях система вносит предложения и ожидает действий администратора. И только полностью автоматизированный режим обеспечивает автоматическое перемещение виртуальных машин на основе расчетов службы мониторинга. VMware, как и большинство экспертов, считает, что полностью автоматизированный DRS — лучший выбор практически для любого кластера.
Важнейшим преимуществом этого режима является быстрое выполнение балансировки кластера. Разрешив планировщику DRS действовать от вашего имени, вы можете решить проблемы с производительностью до того, как они повлияют на работу пользователя.
Совет № 2. Изучите применяемые в DRS формулы восстановления баланса
Следуйте совету n. 1 не означает слепо, без всякого контроля, доверять планировщику DRS. Перейдя в полностью автоматический режим, математическая модель уровня кластера, реализованная в DRS, может быть применена для определения баланса кластера. Эта модель проста для понимания, и когда вы освоите ее, вы сможете определить оптимальную настройку порога миграции. В зависимости от ваших потребностей этот параметр может быть немного ближе к консервативному сегменту спектра или более агрессивному сегменту.
Для начала стоит объяснить несколько вещей. Прежде всего, имейте в виду, что цикл работы DRS запускается каждые 5 минут. Во время каждого последующего запуска DRS анализирует счетчики использования ресурсов на всех хостах в кластере. Затем планировщик вычисляет эти данные, чтобы определить баланс потребления ресурсов в кластере.
Возможно, не так-то просто понять идею кластерного равновесия. Воспользуемся наглядным примером. Представьте себе стол в форме многоугольника; опирается на одну ножку, закрепленную в центре стола. Каждая сторона многоугольной таблицы соответствует одному из хостов в нашем кластере. Нога может удерживать стол в равновесии только в том случае, если вес равномерно распределяется по всем его сторонам.
Теперь представьте, что происходит, когда использование ЦП и памяти на одном хосте становится значительно выше, чем на других. Равновесие будет нарушено, и «стол начнет падать на бок». Чтобы устранить проблему и восстановить баланс, планировщику DRS потребуется переместить одну или несколько виртуальных машин на новый хост.
Но прежде чем выбрать виртуальную машину для перемещения, DRS необходимо определить, действительно ли кластер не сбалансирован. Расчет начинается с определения нагрузки на каждый хост, добавления результатов, полученных для каждой виртуальной машины на данном хосте, и деления полученного значения на общую емкость хоста. Формула выглядит так:
 |
В этой формуле значение Права ВМ включает любые зарезервированные квоты процессора или памяти или ограничения, наложенные на виртуальные машины. Также учитывается запрос ресурсов процессора и размер рабочего набора памяти; оба индикатора динамические. Чтобы получить емкость хоста, вы можете рассчитать общие ресурсы ЦП и памяти для данного хоста и вычесть из этого результата накладные расходы VMkernel, служебную консоль и дополнительную избыточность 6%. Если для данного кластера включены HA и Admission Control, вы также можете вычесть из общего количества дополнительную избыточность, необходимую для получения метрики высокой доступности.
После выполнения вышеуказанных шагов полезно собрать статические данные для следующего шага. Нагрузка на каждый хост уже определена, и это позволяет узнать стандартное отклонение всех нагрузок. Для тех, кто не изучал статистику, поясню: стандартное отклонение показывает, насколько индивидуальная нагрузка кластера отличается от среднего значения нагрузки (что означает, насколько этот кластер несбалансирован). Чем больше стандартное отклонение, тем больше дисбаланс.
Эти значения рассчитываются планировщиком DRS. На рисунке 2 показан снимок вкладки «Сводка демокластера». В этом кластере целевое стандартное отклонение для хоста определено как 0,2 или меньше. Это значение определяет максимальную степень дисбаланса, допустимую для кластера. При более высоких значениях система вмешается, чтобы восстановить баланс. На рисунке 2 мы также видим, что текущее стандартное отклонение для этого кластера составляет всего 0,074, что меньше 0,2. В результате баланс кластера не нарушается. Виртуальные машины перемещать не нужно.
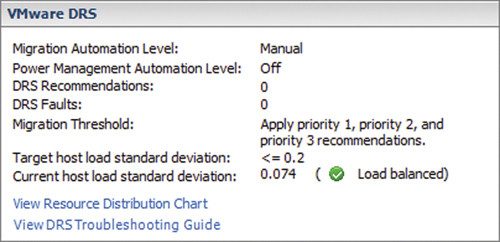 |
| Рисунок 2. Стандартное отклонение целевой и фактической нагрузки на хост |
Рассмотренный пример показывает, как обстоят дела в случае, если DRS приходит к выводу о состоянии равновесия кластера. Но что произойдет, если произойдет резкий всплеск потребления ресурсов одной или несколькими виртуальными машинами? В этой ситуации стандартное отклонение может превысить заданное пороговое значение, и, таким образом, наша воображаемая таблица начнет наклоняться в одну сторону. Чтобы решить эту проблему, вам необходимо перебалансировать нагрузку, переместив виртуальные машины.
Следующая задача для DRS — определить, какие виртуальные машины наиболее эффективны для решения проблемы. На этом этапе DRS моделирует серию перемещений виртуальных машин от одного хоста к другому, чтобы определить все варианты и расположить их в порядке приоритета.
Лучшими вариантами считаются те, которые в наибольшей степени влияют на восстановление баланса кластера и минимизируют риск его нарушения в будущем.
Уровень приоритета любого потенциального действия рассчитывается по следующей формуле:
 |
Скобки в приведенной выше формуле представляют собой математический оператор, который округляет ее содержимое до следующего целого числа. Например, потенциальное перемещение кластера с четырьмя хостами, которое снизит стандартное отклонение нагрузки хоста до 0,14, приведет к приоритету 3. Как можно заключить из приведенной выше формулы, каждому перемещению может быть назначен приоритет от 1 до 5 (чем меньше число, тем выше приоритет движения и тем больше он помогает устранить дисбаланс).
В этой ситуации становится очень важным, как мы определяем параметр порога миграции (рисунок 1). В приведенном выше примере была выбрана центральная настройка порога миграции, которая указывает планировщику DRS автоматически применять рекомендации для любого из приоритетов 1, 2 или 3, игнорируя все остальные рекомендации. Предлагаемые движения, которые имеют менее значительное влияние на ребалансировку кластера, в данном случае движения с приоритетом 4 или 5, игнорируются.
Потенциальное перемещение в приведенной выше формуле имеет приоритет 3. Это значение находится в пределах установленного порога миграции, поэтому DRS переместит соответствующую виртуальную машину на новый хост. Этот процесс определения возможных перемещений, расчета их эффекта и выбора миграции vMotion продолжается до тех пор, пока стандартное отклонение текущего хоста меньше стандартного отклонения хоста.
Имейте в виду, что рекомендации с приоритетом 1 — это всегда особые случаи. Это обязательная миграция, которую необходимо выполнить для решения любых серьезных проблем. Проблемы, связанные с демонстрацией, включают примеры включения режима обслуживания или ожидания, нарушения правила сродства или анти-сродства или ситуаций, когда ресурсы, выделенные для запуска виртуальных машин, увеличивают емкость, превышающую емкость хоста.
понятно, что ваша цель — убедиться, что кластер хорошо сбалансирован с точки зрения нагрузок, но помните: демонстрация слишком большой активности для достижения этой цели может только навредить делу. Использование чрезмерно жестких критериев при определении порогового значения имеет свои недостатки. В конце концов, каждая операция перебалансировки требует одной или нескольких миграций vMotion, а каждая миграция vMotion требует выделения ресурсов. Следовательно, вы должны ставить цели, которые достижимы без особых усилий: вы должны стремиться не к получению идеально сбалансированной системы, а к формированию кластера, который является только достаточно сбалансированным.
Совет № 3. Используйте ограничения с осторожностью
vSphere предлагает обширные (или даже подавляющие) возможности для ограничения использования ресурсов. Администратор может применять правила, согласно которым определенный набор виртуальных машин должен находиться на одном хосте, или правила, согласно которым они должны находиться на разных хостах. Если вы используете vSphere 4.1, вы можете применять правила виртуальных машин к хостам; эти правила определяют группы виртуальных машин, которые должны, не должны, по возможности, должны или не должны работать в группах узлов.
Правила виртуальных машин и хостов позволяют применять бизнес-логику к формулам перебалансировки баланса, используемым планировщиком DRS. Сразу приходят в голову некоторые типичные ситуации: например, если в вашем центре обработки данных используются два виртуализированных контроллера домена Active Directory (AD), запуск обоих серверов на одном хосте ESX может показаться непрактичным. Ведь при потере хоста ESX службы домена перестанут работать. Применяя правило «Разгруппировать виртуальные машины», которое можно запустить из узла «Правило» в окне свойств кластера (рис. 3), вы обеспечите разделение виртуальных машин, даже если впоследствии нагрузки в кластере не будут сбалансированы. Аналогичным образом (хотя и для других целей) вы можете применить правило «Держите виртуальные машины вместе»; Это правило следует использовать в ситуациях, когда виртуальные машины определенной группы взаимодействуют друг с другом в процессе обмена данными или по соображениям безопасности, или в рамках соблюдения требований законодательства.
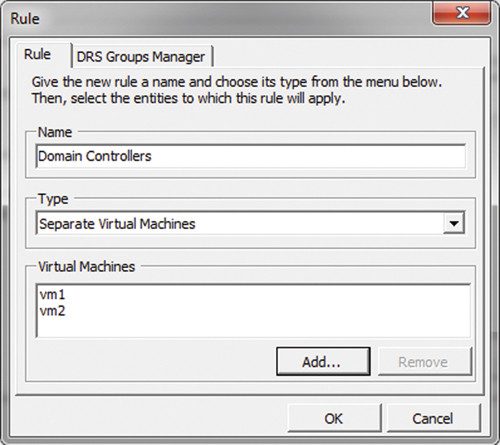 |
| Рисунок 3: Применение правил к виртуальным машинам |
Вы также можете применить настройки распределения ресурсов, такие как общие ресурсы, зарезервированные ресурсы или ограничения. Эти параметры применяются к пулам ресурсов или отдельным виртуальным машинам, как показано на рисунке 4. Зарезервированный ресурс — это количество ресурсов, которое виртуальная машина имеет в любое время в случае конфликта ресурсов. Ограничения не позволяют виртуальным машинам использовать чрезмерное количество ресурсов независимо от того, существует ли конфликт для этих ресурсов. Общие ресурсы определяют относительную важность виртуальных машин, гарантируя, что ресурсы, за которые конкурируют различные системы, переходят к виртуальным машинам, рабочие нагрузки которых являются наиболее важными с точки зрения бизнеса.
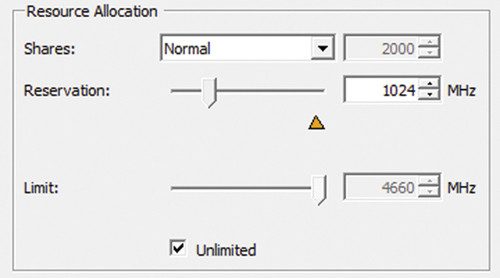 |
| Рисунок 4: Распределение ресурсов процессора для виртуальных машин |
Все эти замечательные инструменты очень полезны в некоторых обстоятельствах, но по мере их появления администраторам приходится манипулировать все новыми и новыми флагами и настраивать все новые ползунки. Кроме того, эти инструменты предоставляют чрезмерно прилежным администраторам множество возможностей для создания ненужных сложностей во имя оптимизации ресурсов.
Проблема с этими настройками не в том, что они неэффективны; Эти инструменты фактически блокируют попытки плохо написанных приложений занять слишком много циклов ЦП хоста или сохранить важную виртуальную машину с ограниченными возможностями в ситуации, когда ресурсов не хватает для всех. Но проблемы возникают, когда чрезмерно усердные администраторы накладывают ненужные ограничения. Если у вас есть возможность что-то ограничить, это не означает, что ограничение должно применяться.
Чтобы понять причину этого утверждения, необходимо понять, как ограничения ресурсов влияют на функционирование DRS. Помните, что DRS в первую очередь занимается балансировкой нагрузки кластера. Расчет балансировки нагрузки начинается с анализа квот ресурсов для каждой виртуальной машины, который включает любые статически назначенные ресурсы или зарезервированные лимиты. Определение этих зарезервированных ресурсов и пределов, в которых они могут быть распределены, излишне усложняет формулы перебалансировки, используемые планировщиком DRS (из подсказки №2). Зарезервированные ресурсы и ограничения помогают сократить общее количество возможных поездок, исключая те, которые нарушают ограничения ресурсов. Кроме того, зарезервированные ресурсы и ограничения могут снизить эффективность любых оставшихся перемещений, поскольку затронутый кластер потребуется перебалансировать на основе недействительных ограничений ресурсов.
Совет № 4. Хостов в кластере не должно быть ни слишком много, ни слишком мало
Деликатная задача правильного распределения виртуальных машин между хостами кластера, возложенная на планировщик DRS, во многом похожа на задачу рассадки гостей за праздничным столом. За каждым столом может разместиться определенное количество гостей; чем больше стол, тем больше людей может разместиться. Если столов не хватает, вы можете усадить за каждый больше людей, но если столиков много, у каждого гостя будет больше места (и это будет намного удобнее для всех).
Однако определение точного количества таблиц — не самая очевидная задача. Если вы пойдете в крайность, вы можете арендовать два больших стола и заставить всех сесть. Другая крайность — аренда большого количества столов, каждый из которых может вместить только несколько человек.
Проблема возникает, если у вас слишком мало или слишком много таблиц (или, возвращаясь к нашему случаю, слишком много или слишком мало серверов ESX). Все участники праздника могут сесть за два достаточно больших стола. Но что, если вдруг окажется, что все члены внушительной семьи не могут поселиться в непосредственной близости от своих родственников? Придется спросить себя, как правильно расставить стулья с двумя столами при большом количестве гостей.
Проблема перераспределения виртуальных машин между серверами ESX — если этих серверов явно недостаточно и в то же время различные системы конкурируют за ресурсы — мало чем отличается от задачи размещения гостей на свадьбе. Если места недостаточно, планировщику DRS требуется больше перемещений виртуальных машин и более сильное воздействие на кластер, чтобы сбалансировать желаемый баланс. Ситуация значительно упрощается, когда кластер состоит из большого количества серверов ESX. Чем больше этих серверов, тем больше возможностей для расчета размещения виртуальных машин.
Но если мы продолжим добавлять все больше и больше хостов, это может зайти слишком далеко. Когда хостов слишком много, возникает совсем другая проблема. Кластер DRS vSphere 4.1 может взаимодействовать с 32 хостами и 3000 виртуальными машинами. И чем больше хостов, а также виртуальных машин включено в кластер, тем больше моделей DRS должен создать, чтобы определить, какая модель наиболее эффективно влияет на кластер. «Прогоны» DRS выполняются с 5-минутными интервалами, поэтому вычисления должны выполняться быстро, прежде чем начнется следующий «прогон». Следовательно, более эффективным решением представляется распределение хостов и виртуальных машин по нескольким кластерам.
В своей книге VMware vSphere 4.1 HA и DRS Technical Deepdive (CreateSpace, 2010) авторы Дункан Эппинг и Фрэнк Деннеман утверждают, что оптимальное количество хостов на кластер в настоящее время составляет от 16 до 24. По их словам, это число обеспечивает достаточно вариантов для загрузки балансирует виртуальные машины между разными хостами в кластере, не создавая ненужных потоков DRS на платформе vCenter.
Совет № 5. Крупные виртуальные машины ограничивают свободу движений
В соответствии с современными представлениями о количестве ресурсов, выделяемых для виртуальных машин, необходимо строго придерживаться принципа — выделять не больше, чем необходимо. Хотя гипервизоры ESX могут использовать различные технологии, чтобы воспользоваться преимуществами выделения памяти, эти процессы добавляют ненужные накладные расходы, которых можно избежать, выделяя только то, что нужно виртуальным машинам. То же самое и с процессорами; в большинстве случаев практическое правило — выделять только один процессор на каждую виртуальную машину.
Однако время от времени возникает необходимость создавать очень большие виртуальные машины с большим объемом выделенной памяти и с несколькими процессорами. Эти виртуальные машины могут действовать как серверы баз данных или мощные серверы приложений. Но независимо от рабочей нагрузки эти большие виртуальные машины усложняют вычисления, выполняемые планировщиком DRS. Легко видеть, что в ситуации обострения конкуренции за ресурсы большую виртуальную машину можно разместить только в ограниченном количестве мест. Некоторым хостам в кластере может не хватить мощности для запуска большой виртуальной машины. У других может не хватить физических ресурсов, чтобы даже поставить на них эту машину. Хотя объем ресурсов, выделяемых каждой виртуальной машине, определяется рабочими нагрузками, необходимо убедиться, что кластер имеет достаточную емкость для эвакуации большой виртуальной машины. В противном случае возможности балансировки нагрузки DRS будут ограничены.
Все не так просто, как кажется
VMware проделала большую работу по маскированию фоновой обработки DRS с помощью простого интерфейса. К сожалению, этот простой интерфейс обманывает сложные вычисления, которые на самом деле необходимы для правильной балансировки нагрузки в кластере. Дальновидные администраторы уделяют пристальное внимание мониторингу данных, отображаемых в свойствах каждого кластера, и следят за тем, чтобы структура кластера давала планировщику DRS свободу принимать правильные решения. В противном случае вы можете снизить производительность и упустить возможность оптимизировать дорогостоящие физические ресурсы.
Было бы ошибкой полагать, что DRS может решить любую проблему в сети. Следуйте пяти советам из этой статьи. Таким образом, вы сможете обеспечить работоспособность кластера даже в ситуации постоянного изменения статистики использования ресурсов.